


Extract data from an entire PDF folder in minutes
My simple template to do this using Python and OpenAI models


Earlier this year, I wrote a post about how you can use Python with large language models (LLMs) — the technology behind Generative AI like ChatGPT — to extract, collect, and analyze datasets from web pages. This is done by querying OpenAI’s API (Application Programming Interface) with prompts.

The approach is useful when you want to process a long list of URLs to create a precise data table in a specific format (e.g., string, timestamp, number) and then export it to a CSV file for use in forecasting models or further analysis.
In this post, I’ll demonstrate how you can apply the same technique to extract data from a folder of PDF documents. This way, you can avoid the file upload limits of the ChatGPT UI.
I will show how I use prompt templates to provide plain-English instructions to an OpenAI model, systematically collecting structured data on R&D expenditure from financial statements. You could then extend this further by automating the Python script to run at a regular interval (e.g., monthly), or every time a new file is added.

The notebook with the complete code is available on my Gumroad store. It’s a simple template that opens in Google Colab, allowing you to start running it directly from your browser, upload your own PDF documents, and modify the prompts.
Why use LLMs and Python for this task?
I was once given the tedious task of collecting various metrics from financial statements for the largest European listed companies by market capitalization. A task like this used to take 1–2 days, but using an LLM model with Python can get the job done in just a few minutes.
Python libraries like camelot can convert tables in PDFs to DataFrames, but they lack flexibility when numbers are embedded in text instead of tables. Their output can be horrible, often requiring extensive post-processing to get the desired format. You also need to adapt it to various table styles in different sources.
Some suggest using Optical Character Recognition (OCR) to convert PDFs into images and then extract text, but the code can be complex and convoluted.
Attempting such tasks directly in a ChatGPT UI can quickly hit context window limits with multiple documents (more on this later) or file upload limits.
Using Python with prompt templates allows you to automate the process by systematically applying the same prompt to each source in a loop. The script can then be automated to run on a regular basis without manual overhead, see my other post on how to do this.
How it works
(1) Load docs
First, we need to extract the text from all the PDF files in our directory (‘financial_statements’), which contains financial statements for Apple and Google.
To accomplish this, I use the PyPDFLoader and DirectoryLoader modules from the LangChain library.
LangChain is an open-source library that bridges LLMs like ChatGPT with other Python modules, simplifying application development.
The code snippet below will load only the PDF files and ignore others before storing them in the docs object.
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
loader = DirectoryLoader('financial_statements/', glob="**/*.pdf", loader_cls=PyPDFLoader)
docs=loader.load()We then group the content by its source, making it easier to cross-reference results later.
# Group documents by their metadata source and merge their content
content_by_source = defaultdict(str)
for doc in docs:
source = doc.metadata['source']
content_by_source[source] += doc.page_content The code stores the source and text content from each statement in their entirety within a Python dictionary, {source: content}, inside content_by_source. The first source in the folder is stored like this:
{'financial_statements/2022q4-alphabet-earnings-release.pdf':"Alphabet Announces Fourth Quarter and Fiscal Year 2022 Results...}(2) Create a prompt template
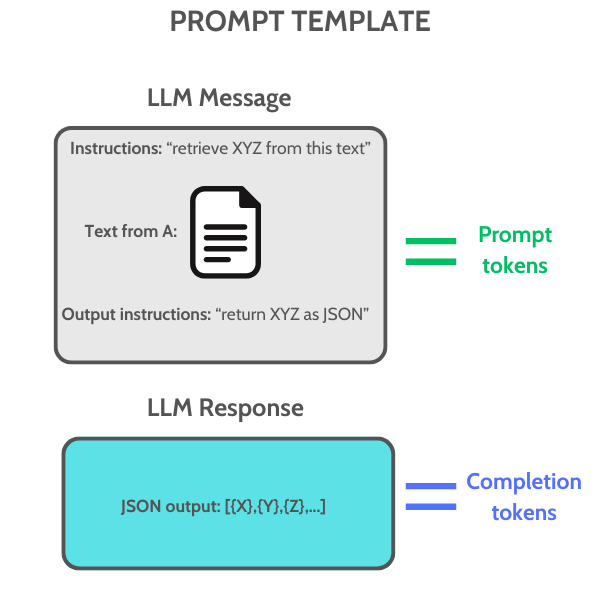
Now, we need to create a prompt template that contains the instructions for what we want to accomplish.
This corresponds to the LLM message in the diagram below. Essentially, it’s similar to what you would type as a prompt in the ChatGPT UI. The template includes instructions for what to extract from the PDF, all the text/content from the document, and the desired format for the output.

The output from the LLM response in this case will be in JSON format, a flexible representation for storing data. It can easily be converted into a Pandas DataFrame and, finally, a CSV file.
Below is the prompt template for this task, where {text} represents the content from each statement and {format instructions} specifies the desired output format.

It’s best to be as specific as possible with your instructions. This may require some iteration with a smaller set of documents initially to check the accuracy of the results. My use case is straightforward, but you can include more complex instructions, such as adding a column that indicates whether a statement is bullish or bearish for the stock price.
Hack: Use ChatGPT or Gemini within Google Colab to generate an effective prompt tailored to your specific task.
The {format instructions} of the prompt tempate is this:
# format_instructions:
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"financial_year": string // Financial year
"rd_figure": int // the figure for research and development
"company_name": string // the name of the company
}
```This standard instruction is generated using the StructuredOutputParser from LangChain, which includes all the response schemas.
from langchain.output_parsers import StructuredOutputParser
...
response_schemas = [
financial_year_schema,
rd_schema,
company_name_schema,
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
...The response schemas define how we want the response to be formatted for each column in our dataset.
from langchain.output_parsers import ResponseSchema
...
rd_schema = ResponseSchema(
name="rd_figure", description="the figure for research and development", type='int'
)
...This prompt template (‘extract template') will serve as the basis for all messages sent to the LLM model via prompt.
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(template=extract_template)(3) Apply the template to all documents
Using the prompt template, we can write a Python script that loops over the content from each source and stores the response for each iteration.

Below is a snippet showing how to loop through each source and its contents, generate a response, convert it to JSON format, and append the result to a Python list.
Remember to create an account with OpenAI and generate your API key first.
# Set OpenAI API key
os.environ["OPENAI_API_KEY"] = "<YOUR APIR KEY>"
chat = ChatOpenAI(temperature=0.0, model="gpt-4o-mini") # initialize model
output_list = [] # python list to store data
# Loop prompt over source
for source, content in content_by_source.items():
messages = prompt.format_messages(text=content, format_instructions=format_instructions)
response = chat(messages)
# Save response in the desired output
parsed_response = output_parser.parse(response.content)
parsed_response['source_doc'] = source # create column with source name
output_list.append(parsed_response)The model we used above was ‘gpt-4o-mini’. You can see what models are available here. What model you choose depends on the complexity of your task, the cost of each model, and the context window.
The cost of using an OpenAI model depends on the input tokens (prompt tokens) and output tokens (completion tokens) used. Tokens represent how the model processes text by dividing it into smaller units, with each model using its own algorithm to handle them.
The cost is then calculated based on the cost per token. Thankfully, there is a function called get_openai_callback that you can embed into your loop to automatically calculate this for you.
from langchain_community.callbacks import get_openai_callback
...
for source, content in content_by_source.items():
messages = prompt.format_messages(text=content, format_instructions=format_instructions)
with get_openai_callback() as cb:
response = chat(messages)
# Access token and cost information directly from the callback object (cb)
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")
...To give you an idea of the cost, my entire loop processed 43 pages from 8 different sources and totaled just USD 0.004818—not too bad!

The context window refers to the total tokens (prompt + completion) allowed for each query in your loop. The gpt-4o-mini model has a context window of 128k, and the maximum total tokens I used for any single query was about 7k, which was well within the limit.
(3) Save output as csv
Lastly, you can convert the JSON list into a Pandas DataFrame, save it as a CSV file, and download your neatly formatted dataset.
# Convert your json list into a pandas DataFrame
json_list = json.dumps(output_list)
df = pd.read_json(json_list)
# Save to CSV
df.to_csv('output.csv', index=False)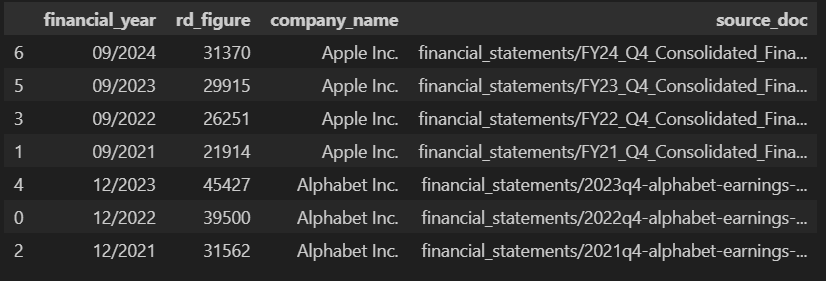
Try it yourself
If you found this useful, check out the template on my Gumroad store and start loading your own PDF files directly in your browser.
Even if you already have some text data collected, using prompt templates with OpenAI’s API can help you build structured tabular datasets quickly. For example, The Economist used this technique to process MPs' disclosures of financial interests and second jobs.
Let me know your thoughts in the comments section—I’d love to hear about the use cases you have for it!
One final thing…
This newsletter is all about empowering everyday people to incorporate Python into their work.
However, 1.1 billion students globally still lack internet access and cannot read newsletters like this or access the online education many of us take for granted.
With the giving season underway, I wanted to highlight Give Internet. Their mission is to transparently sponsor internet access and laptops for high school students in need.
They partner with organizations like MIT and the University of Geneva and currently operate in 14 countries, including Georgia (Eastern Europe), Kenya, Uganda, and India.

Here are some numbers of their impact so far:
2,030 households connected to the internet through the program
2,958 laptops distributed
3003 students reached
Any donations made through this link will be doubled by one of their founding members.
By supporting Give Internet, you’ll be helping to educate the next generation of developers, designers, teachers, healthcare workers, and entrepreneurs.
Pretty interesting. I've done something similar before myself. But don't you think chatbots like ChatGPT will always be a better solution?