


Extracting data from web pages is a valuable skill when you’re struggling to get data from official sources, or if you simply want to automate manual data collection.
In economics and finance, it is often used to source real-time data given the long lags in official government data releases.
It was used extensively during Covid when policymakers and investors needed timely data to take action quickly. For example, postings on job websites helped analysts gauge the health of the labour market, or data from e-commerce sites that could capture price fluctuations.
Web scraping can give you access to unique datasets that immediately set your work apart.
It’s is also useful to gather data from text sources (e.g. for sentiment analysis) that sometimes only exist on websites, like press releases. This is exactly what I will do in this post—I will give a walk-through of how you can scrape text from the Federal Reserve website.
This will set the foundation for more advanced tasks later, like programmatically scraping and building an entire dataset, submitting online forms, and handling more complex websites with Selenium.1
What does BeautifulSoup actually do?
A basic web page is like an organized document written in HTML, a programming language that tells your browser how to display text, images, and links.
It's organized with tags such as <p> for paragraphs or <div> for sections, which give the page its structure.
You can actually see the raw HTML structure when you right-click and hit “inspect” on an website element.

Instead of writing code to search through the raw HTML—which can be messy and unique for every web page—BeautifulSoup reads this HTML and turns it into a neat, structured tree. This makes it much easier to find and pull out the specific bits of information you need.
The Basic Methods of BeautifulSoup
Below is a very basic example of HTML for a web page with two links. It includes anchor tags, represented by <a>, which create hyperlinks that allow users to click and navigate to another page, section, or resource. These tags typically include an href attribute that specifies the destination URL.

We can parse this HTML into a soup object using BeautifulSoup’s “html.parse.”
To find all the elements with an <a> tag, we can use soup.find_all("a").
Output: [
<a href="https://www.example.com" title="Example Link">Click here</a>,
<a href="https://www.example2.com" title="Example Link 2">Click here too</a>
]To only find the first element with an <a> tag, use soup.find("a"):
Output: <a href="https://www.example.com" title="Example Link">Click here</a>If we focus on the first tag only, we can easily extract different parts of it:
first_link_tag.get("href")→ grabs the value ofhref("https://www.example.com")first_link_tag.get("title")→ returns the title ("Example Link")first_link_tag.get_text()→ extracts the text ("Click here")
Real example: Extract elements from the Federal Reserve website
The full code for the walkthrough is at the end of the post. I know I always bang on about it but Google Colab is the best way to follow along and run the code yourself.
First, we define the URL of the webpage we want to scrape. In this case, we're going to use a Federal Reserve press release from Jan 2025.
We’ll then use the requests library to fetch the raw contents of the page and parse this HTML content using BeautifulSoup.
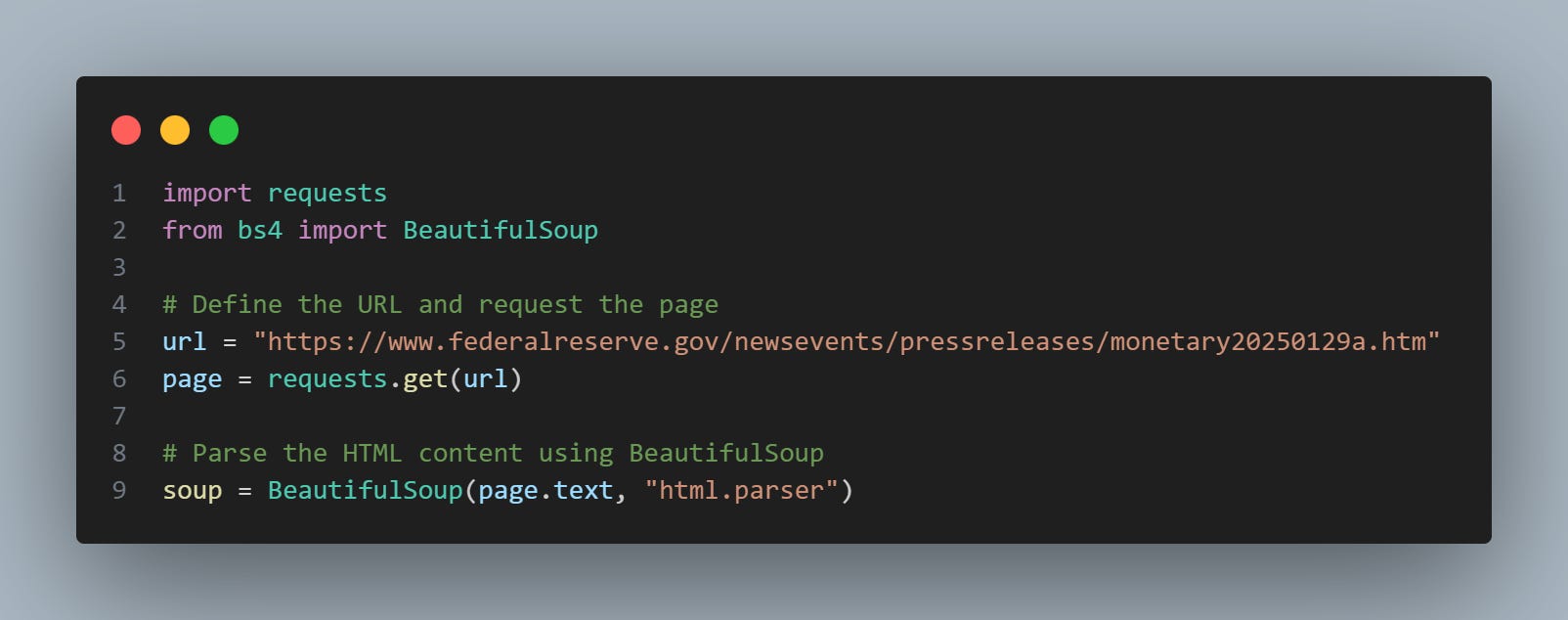
If we want to extract the press release text specifically, we can use the find() function from the soup object. To know what to find, we simply highlight this paragraph in our browser → right-click → ‘inspect’ and see the specific element.

We can see it has a <div> tag with the string "col-xs-12 col-sm-8 col-md-8," which is a set of CSS classes to control how elements are sized and arranged on different devices.
We can pass this information as parameters in the find() method to return the exact <div>, and then use the get_text() method on it to extract the full text.

print(text)
-> Recent indicators suggest that economic activity has continued to expand at a solid pace. The unemployment rate has stabilized at a low level in recent months, and labor market conditions remain solid. Inflation remains somewhat elevated.The Committee seeks to achieve maximum employment and inflation at the rate of 2 percent over the longer run. The Committee judges that the risks to achieving its employment... What if we wanted to find the links for all FOMC statement press releases from 2024 in order to extract the text from each one programmatically?
We can load the press release page for 2024 and use the find_all() function to get all anchor tags.

The output of all_links:

This gives us a lot of links—many of which we don’t want. In fact, we only want relative links where the href starts with “/newsevents/pressreleases/” and that end with “a.htm” for FOMC statements.
'<a href="/newsevents/pressreleases/monetary20241218a.htm"><em>Federal Reserve issues FOMC statement</em></a>'We can write a loop to iterate over all links and only get the href values that start and end with the string we want. We then add these href values to the base URL and collect them in a list (press_release_links).
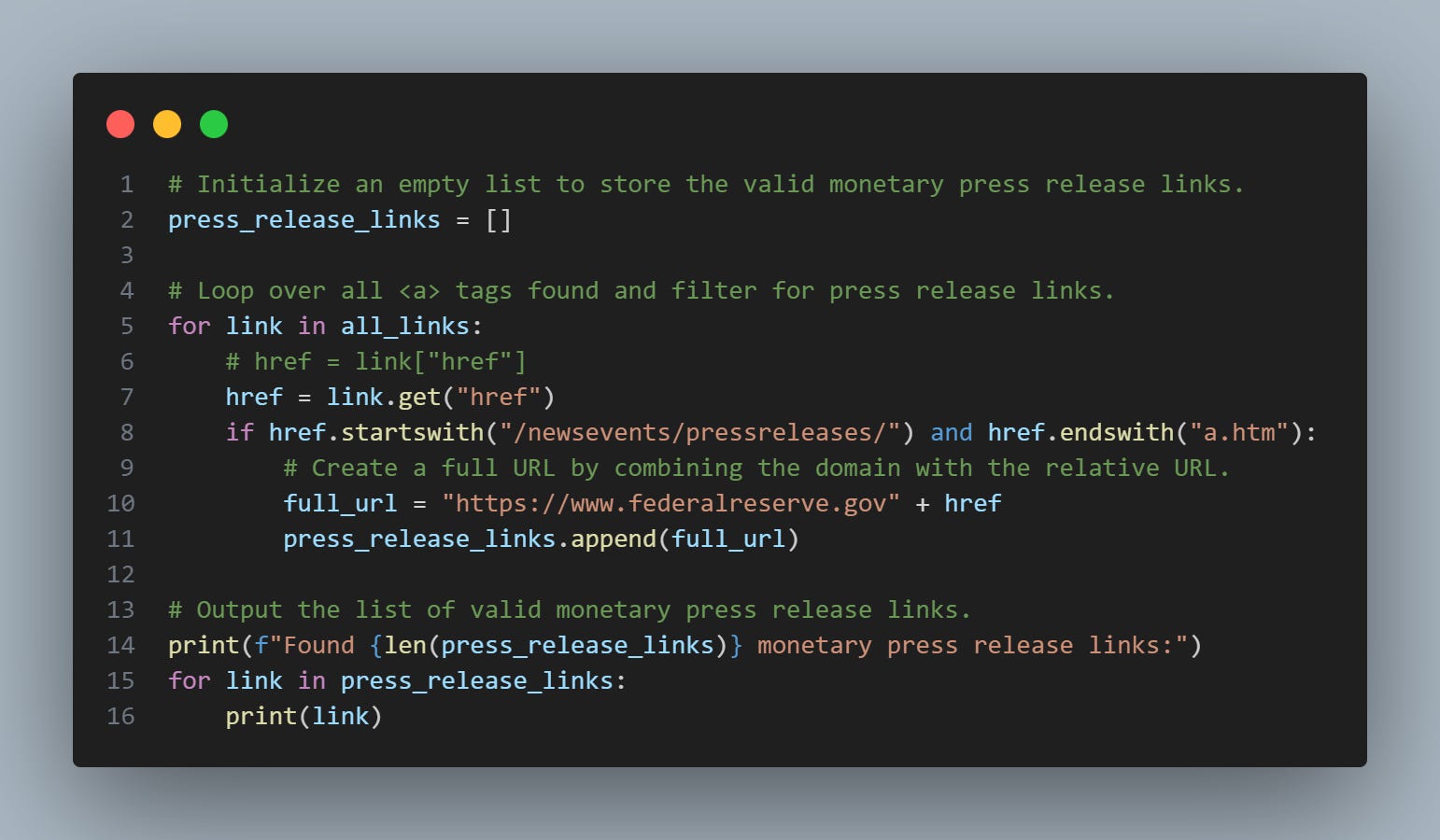
Below are the collected links that we wanted. One could then easily loop through each link to retrieve the FOMC statement text with find() and get_text(), as we did earlier.

Hopefully, this tutorial gives you a good starting point on what’s possible with Python when it comes to web scraping.
Note that it’s always better to use a data API if the website provides one, like FRED’s.

This will always be superior to web scraping since the data is structured, and you won’t be at the mercy of changes to a website’s structure.
Full code snippet
import requests
from bs4 import BeautifulSoup
############### Example dummy html ###############
html_extended = """
<a href="https://www.example.com" title="Example Link">Click here</a>
<a href="https://www.example2.com" title="Example Link 2">Click here too</a>
"""
# Initialize the soup object
soup = BeautifulSoup(html_extended, "html.parser")
# Find all <a> tags
all_links = soup.find_all("a")
print(f"All links: {all_links}")
# Find the first <a> tag
first_link_tag = soup.find("a")
print(f"First link: {first_link_tag}")
# Use .get() to retrieve the value of the href attribute
href_value = first_link_tag.get("href")
print(f"Link href: {href_value}")
# Use .get() to retrieve the value of the title attribute
title_value = first_link_tag.get("title")
print(f"Link title: {title_value}")
# Use .get_text() to retrieve the value of the href attribute
html_text = first_link_tag.get_text()
print(f"Link text: {html_text}")
############### Example Fed ###############
# Define the URL and request the page
url = "https://www.federalreserve.gov/newsevents/pressreleases/monetary20250129a.htm"
page = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(page.text, "html.parser")
# Find the first <div> tag with a specific class
first_div = soup.find("div", class_="col-xs-12 col-sm-8 col-md-8")
text = first_div.get_text(strip=True)
# Extract text from multiple links
url = "https://www.federalreserve.gov/newsevents/pressreleases/2024-press-fomc.htm"
response = requests.get(url)
# Parse the HTML content using BeautifulSoup.
soup = BeautifulSoup(response.text, "html.parser")
# Find all <a> tags with an href attribute.
all_links = soup.find_all("a", href=True)
# Initialize an empty list to store the valid monetary press release links.
press_release_links = []
# Loop over all <a> tags found and filter for press release links.
for link in all_links:
# href = link["href"]
href = link.get("href")
if href.startswith("/newsevents/pressreleases/") and href.endswith("a.htm"):
# Create a full URL by combining the domain with the relative URL.
full_url = "https://www.federalreserve.gov" + href
press_release_links.append(full_url)
# Output the list of valid monetary press release links.
print(f"Found {len(press_release_links)} monetary press release links:")
for link in press_release_links:
print(link)When scraping websites, it's a good idea to check the site's terms of service and any relevant copyright or privacy laws first. This helps you understand what’s allowed, especially if you're planning to use the data commercially. You also shouldn’t overload a website with requests, and there are frameworks to make requests at intervals to help achieve this.